
Sélecteur d’effort Claude Code : choisissez le bon niveau
low, medium, high, xhigh, max... et maintenant ultracode ! Découvrez les niveaux d'effort de Claude Code et choisissez le bon pour vos tâches, des plus simples aux plus complexes !


La semaine dernière, après l’annonce d’Anthropic concernant Opus 4.8 et les Dynamic workflows, j’ouvre Claude Code et les settings pour voir les nouveautés. Et là, je vois un truc que je n’avais pas vu la semaine d’avant : Dynamic worflows, qui ajoute notamment un nouveau sélecteur d’effort (sur le plan Pro) en plus des déjà connus low, medium, high, xhigh (extra) et max. Ultracode.
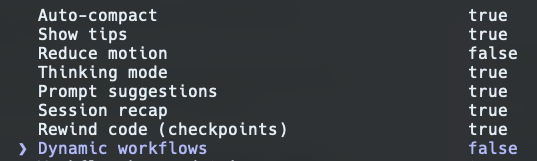
high était coché par défaut. Alors que j’avais une feature à compléter, j’ai choisi xhigh sans trop savoir pourquoi, avant de tester ultracode. Résultat : la session a tourné deux fois plus longtemps, consommé trois fois plus de tokens qu’habituellement, et produit... probablement le même résultat que j’aurais eu en high.
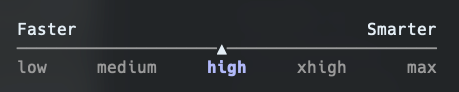
Si vous avez déjà eu cette même réaction (celle de cliquer au hasard sur max parce que ça semble mieux), cet article est pour vous.
Ce que vous saurez à la fin :
Ce que le sélecteur d’effort change vraiment (spoiler : ce n’est pas que la qualité)
La différence entre xhigh et ultracode (beaucoup de gens confondent)
Quel niveau utiliser selon le type de tâche
Pourquoi “Max” sur tout est une erreur qui coûte cher
Un guide décisionnel à coller dans votre
CLAUDE.md
Ce que le sélecteur d’effort fait vraiment
Il faut d’abord détruire une idée reçue.
La plupart des gens pense que l’effort contrôle la “qualité” de Claude. Plus d’effort = meilleure réponse. C’est vrai en partie, mais c’est surtout vrai pour les tâches complexes. Sur une tâche simple, augmenter l’effort ne rend pas la réponse meilleure. Ça la rend juste plus lente, plus longue, et parfois pire : le modèle commence à sur-analyser, à douter de lui-même, à produire de l’overthinking sur un problème qui n’en avait pas besoin.
Ce que le sélecteur contrôle vraiment, c’est la quantité de tokens que Claude alloue à sa réflexion interne avant de répondre. Et ça a des effets en cascade sur tout : le texte généré, les appels d’outils, les sous-agents, les commentaires de code.
La documentation Anthropic est claire là-dessus : l’effort affecte tous les tokens de la réponse. Pas juste la partie thinking.
À effort faible, Claude va droit au but. Il fait moins d’appels d’outils, évite le préambule, confirme ses actions avec un message court. À effort élevé, il explique son plan avant d’agir, fait plus d’appels d’outils, documente mieux le code.
On n’a donc pas affaire ici à un simple curseur de qualité, mais plutôt de profondeur de raisonnement.
Bien comprendre les cinq niveaux
low : le sprint
Le niveau minimum. Claude répond depuis ses connaissances, sans boucle de raisonnement significative. C’est rapide et peu coûteux.
Je l’utilise pour les sous-agents dans un workflow. Si j’ai un agent principal qui délègue X petites tâches parallèles (extraire un composant, renommer une variable, ajouter un type TypeScript manquant), je passe chaque sous-agent en low. Ils font une seule chose bien définie, inutile qu’ils “réfléchissent” pour ça.
Aussi utile pour les questions factuelles courtes, les reformulations simples, la classification d’inputs dans un pipeline.
En revanche, ce niveau est à éviter pour tout ce qui demande de considérer plusieurs approches ou de détecter des effets de bord.
medium : le quotidien
Un budget de réflexion modéré. Claude raisonne sur les tâches à 2-3 étapes mais ne va pas au fond des cas limites.
C’est le niveau que j’aurais dû utiliser la semaine dernière sur ma simple refacto. Un composant, un problème clair, sans d’ambiguïté architecturale.
Ce niveau est bon pour des ajouts de tests sur du code existant bien structuré, de la génération de boilerplate avec un pattern établi, des résumés de PR, des revues de code légères…
high : le défaut, et c’est bien
C’est le niveau par défaut. Anthropic a choisi ce réglage pour une raison : il représente le meilleur équilibre qualité/coût pour la majorité des tâches de développement.
Ne le changez pas à la légère.
Vous pouvez l’utiliser pour une implémentation de features avec plusieurs fichiers impliqués, debug d’une régression, revue de code avec implications de sécurité, tout ce qui “compte” sans être une décision architecturale critique.
extra / xhigh : le travail de fond
Là, les choses deviennent intéressantes.
Extra (appelé xhigh dans l’API, j’y reviens) alloue un budget de tokens substantiellement plus grand que high. C’est pensé pour les sessions longues, les tâches qui dépassent 30 minutes, les workflows qui enchaînent de multiples appels d’outils.
D’ailleurs, Anthropic recommande de commencer par Extra pour tout le code et le travail agentique.
J’ai mis du temps à comprendre la nuance. Extra, c’est le niveau pensé pour les développeurs qui utilisent Claude Code sérieusement, pas pour les curiosités occasionnelles. Si vous êtes en train de faire un vrai travail d’implémentation sur un projet en prod, Extra est votre point de départ naturel.
Il faut donc l’utiliser pour les refactors multi-fichiers complexes, l’implémentation d’une feature end-to-end, sessions de debug sur un bug à effets de bord multiples ou tout workflow avec des appels d’outils en cascade.
Attention cependant, si vous passez en Extra ou Max, pensez à configurer un max_tokens élevé dans vos settings. Anthropic recommande de partir de 64 000 tokens. Si vous ne le faites pas, Claude pourrait être coupé en plein raisonnement.
max : le cas exceptionnel
Budget maximum. Aucune contrainte sur le nombre de tokens de réflexion.
Je l’utilise rarement, raiment rarement, je pense je peux même dire “jamais”. Parce que sur la majorité des tâches, max coûte bien plus qu’extra pour un gain de qualité marginal. Pire, sur les tâches structurées ou bien définies, Max peut produire de la sur-analyse. Claude tourne en rond sur des edge cases qui ne se produiront jamais.
Ce niveau est donc à réserver pour les problèmes où vous avez constaté que Extra ne suffit pas.
ultracode
C’est là que beaucoup de gens se perdent.
Ultracode apparaît dans le menu d’effort de Claude Code, juste en dessous de Max. Beaucoup pensent que c’est un sixième niveau, encore plus puissant que Max, mais ce n’est pas le cas.
Ultracode ne figure pas comme niveau d’effort séparé dans l’API. C’est une combinaison de deux choses : le niveau xhigh (Extra) + une permission accordée à Claude Code de lancer des workflows multi-agents de son propre chef.
En clair : quand vous passez au niveau ultracode, vous dites à Claude “tu peux décider toi-même de spawner des sous-agents et d’organiser le travail en pipeline”. C’est ce qui produit des sessions spectaculaires comme celle qu’on a vu circuler sur Reddit où des utilisateurs se vantent d’avoir lancé 70 agents automatiquement sur une recherche, organisés en 4 phases.
Honnêtement, je ne suis pas un grand fan des sessions multi-agents, j’aime bien contrôler régulièrement ce qui est fait. Cependant, vous pouvez utiliser ce niveau pour les tâches vraiment ouvertes où vous préférez déléguer l’architecture du workflow à Claude plutôt que de la définir vous-même. C’est puissant, mais c’est aussi potentiellement très gourmand en tokens.
Le guide décisionnel pour un projet React en prod
Voilà ce que j’ai fini par mettre dans mon CLAUDE.md après avoir testé les combinaisons sur mon projet principal (une app Next.js / React / TypeScript / Tailwind CSS).
Si vous l’utilisez, vous verrez que le niveau en bas à droite indiqué par Claude Code reste sur le niveau choisi par défaut, c’est normal. Claude peut adapter le niveau d’effort par réponse individuelles selon vos instructions, le contexte, ou si vous le demandez explicitement.
La skill /effort vous indique le niveau par défaut, mais des overrides individuels peuvent prendre le dessus.
## Niveaux d'effort : règles
### low
- sous-agents avec tâche unique et bien définie
- classification d'inputs dans un pipeline
- questions factuelles courtes (noms de fichiers, configs existantes)
### medium
- ajout de tests sur du code existant structuré
- boilerplate avec pattern établi (nouveau composant depuis un template)
- résumé de PR ou de diff
- renommages et extractions simples
### high (défaut, ne pas modifier sans raison)
- revue de code avec implications de sécurité
- debug d'une régression sur un seul fichier
- implémentation d'une feature simple (1-3 fichiers)
### extra / xhigh
- implémentation end-to-end d'une feature (>3 fichiers)
- refactor architectural d'un module
- session de debug sur un bug à effets de bord
- tout workflow avec appels d'outils en cascade
### max
- décisions architecturales critiques (migration, découpage)
- audit de sécurité sur code sensible
- seulement si extra s'est montré insuffisant sur la même tâche
### ultracode
- recherches profondes et ouvertes sur le codebase
- tâches où je préfère déléguer l'organisation du workflow
- jamais sans avoir configuré des limites dans CLAUDE.md au préalableEn utilisant ces instructions, vous allez faire une vraie découverte : le niveau low pour les sous-agents est amplement suffisant. Avant, mes workflows avaient tous les sous-agents en high par défaut, probablement comme vous. Passer les sous-agents scoped (tâche unique, bien définie) en low réduira le coût de vos sessions sans impacter la qualité.
La commande rapide dans Claude Code
Si vous ne voulez pas changer le réglage par défaut mais ajuster ponctuellement, utilisez /effort en début de session :
/effort extraou directement dans votre settings.json au niveau projet :
{
"env": {
"CLAUDE_CODE_DEFAULT_EFFORT": "xhigh"
}
}Note : dans l’API et les fichiers de config, le niveau s’appelle xhigh, pas extra. C’est le même niveau, deux noms selon la surface.
Ce que vous pouvez faire maintenant
Prêt à utiliser les niveaux d’effort à bon escient et faire des économies de tokens ?Je vous propose 2 actions pour 15 minutes en tout :
Copiez le guide décisionnel ci-dessus dans votre
CLAUDE.md.Testez low pour vos sous-agents : si vous utilisez des workflows multi-agents, passez vos sous-agents scoped en low cette semaine.
Vous étiez en high / max sur tout sans y penser ? Dites-moi tout en commentaires ! Et si ça vous a aidé à y voir plus clair, j’en suis ravi ! Un ❤ fait toujours plaisir :)
On se retrouve vendredi, pour la veille de la semaine !
— Philippe 🐔